
Plonk Pigeonholing
A comparative study of classical TF-IDF and transformer-based approaches for wine variety classification, exploring the tradeoffs between interpretability and performance in domain-specific text analysis.
Overview
Domain-specific text classification poses unique challenges due to overlapping vocabulary and nuanced semantic structure. In wine tasting notes, descriptors like “fruity,” “oaky,” or “smooth” appear across multiple grape varieties, making classification particularly difficult for traditional bag-of-words approaches.
This project compares two fundamentally different approaches to wine variety classification: a classical pipeline using TF-IDF encoding, singular value decomposition, and error-correcting output codes (ECOC) against a modern transformer-based DistilBERT model. Using a corpus of 150,000 wine tasting notes from Wine Enthusiast, I evaluated both methods on their ability to predict grape variety from textual descriptions.
The results reveal a striking performance gap—while the classical approach achieves respectable accuracy through interpretable feature engineering, the transformer model’s contextual understanding dramatically improves classification, particularly for stylistically similar wine varieties. This study illuminates the fundamental tradeoff between model interpretability and predictive performance in specialized domains.
Role & Context
I developed this comparative analysis as the final project for Quantitative Engineering Analytics 1 at Olin College, working alongside Allie Vu over the course of one intensive week in Fall 2025.
The motivation came from wanting to understand how classical NLP techniques stack up against modern transformers on a concrete, domain-specific task. Wine tasting notes provided an ideal testbed—rich descriptive language with subtle class boundaries that would challenge both approaches differently.
Tech Stack
- Python — Core implementation language
- scikit-learn — TF-IDF vectorization, SVD, ECOC classification
- transformers — DistilBERT model and tokenization
- PyTorch — Deep learning framework for transformer fine-tuning
- pandas — Data manipulation and preprocessing
- matplotlib/seaborn — Visualization and performance analysis
- numpy — Numerical computations
Problem
Text classification methods vary dramatically in their balance between interpretability and performance, particularly when dealing with domain-specific language where class boundaries are subtle. Traditional approaches like TF-IDF offer clear feature attribution but may miss contextual nuances, while transformers capture semantic relationships at the cost of explainability.
Wine tasting notes exemplify this challenge perfectly. Descriptions often use overlapping vocabulary across grape varieties—terms like “cherry,” “vanilla,” or “mineral” appear in reviews for multiple wine types. The question becomes: can classical feature engineering compete with contextual embeddings when vocabulary alone provides insufficient discriminative power?
This matters beyond wine classification. Many specialized domains—medical notes, legal documents, technical specifications—face similar challenges where context and subtle semantic differences drive classification decisions.
Approach / Architecture
I implemented two distinct pipelines to isolate the impact of representation learning versus classification methodology.
Classical Pipeline: TF-IDF + SVD + ECOC
This approach follows traditional NLP wisdom: convert text to numerical features, reduce dimensionality, then classify.
Text → TF-IDF Vectorization → SVD Dimensionality Reduction → ECOC SVM → Predicted VarietyTF-IDF encoding emphasizes words that are frequent within individual reviews but rare across the corpus, theoretically highlighting variety-specific descriptors. SVD then projects this high-dimensional sparse representation into a lower-dimensional latent space, capturing the dominant patterns in wine descriptions. Finally, error-correcting output codes extend binary SVM classifiers to handle the multi-class problem.
Transformer Pipeline: DistilBERT
The transformer approach bypasses explicit feature engineering entirely, learning contextual representations end-to-end.
Text → Tokenization → DistilBERT Encoder → Classification Head → Class ProbabilitiesI fine-tuned a pretrained DistilBERT model directly on wine tasting notes, allowing it to learn domain-specific patterns while leveraging its general language understanding. The model outputs probability distributions over grape varieties, naturally handling the multi-class classification.
Key Features
- Comprehensive comparison of classical vs. modern NLP approaches
- Domain-specific evaluation on wine variety classification task
- Interpretable dimensionality analysis through SVD component visualization
- Detailed confusion matrix analysis revealing class-specific performance patterns
- Scalability demonstration with both 6-class and 20-class experiments
- Performance visualization across multiple metrics (accuracy, recall, precision)
Technical Details
Dataset Preparation
The Wine Enthusiast corpus contained approximately 150,000 reviews spanning hundreds of grape varieties. I focused on the top 6 most frequent varieties to ensure sufficient training data while maintaining class balance:
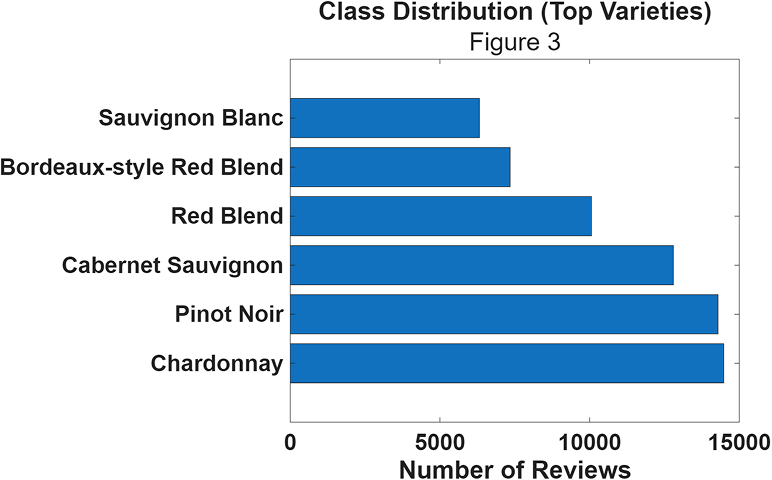
The distribution shows reasonable balance, with Chardonnay being most frequent (~15,000 samples) and Sauvignon Blanc least frequent (~7,000 samples). I used an 80/20 train/test split with held-out validation.
Classical Pipeline Implementation
The TF-IDF vectorization produced extremely high-dimensional sparse representations—over 50,000 features for the full vocabulary. SVD became crucial for computational tractability and noise reduction.
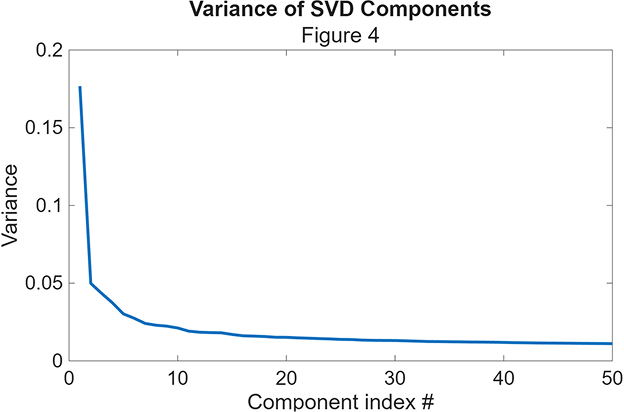
The variance plot reveals a sharp drop-off after the first few components, with diminishing returns beyond 50 dimensions. This elbow motivated my choice to retain 50 SVD components, capturing the dominant latent structure while remaining computationally efficient.
The 2D projection of wine descriptions onto the largest SVD components shows the fundamental challenge:
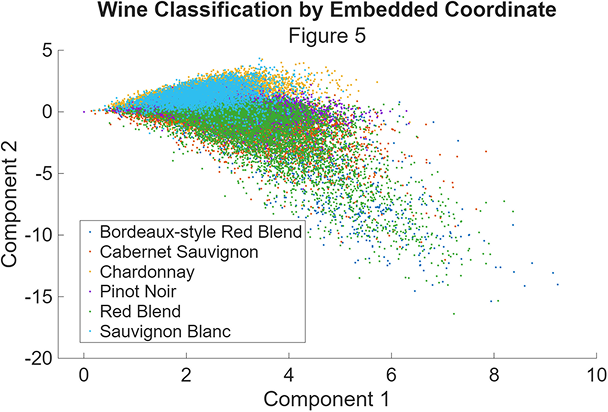
While some clustering is visible, there’s substantial overlap between varieties, particularly among red wines. This visualization immediately suggests why the classical approach struggles—the linear combinations of TF-IDF features don’t cleanly separate the classes.
Transformer Implementation
I fine-tuned DistilBERT using standard practices: freezing early layers, adding a classification head, and training with a small learning rate to preserve pretrained representations while adapting to the wine domain.
The key insight was letting the model learn contextual relationships between descriptors. Where TF-IDF treats “cherry notes with oak aging” as independent terms, BERT understands their semantic relationship and how this combination might indicate specific varieties.
Performance Analysis
The results demonstrate a dramatic performance gap:
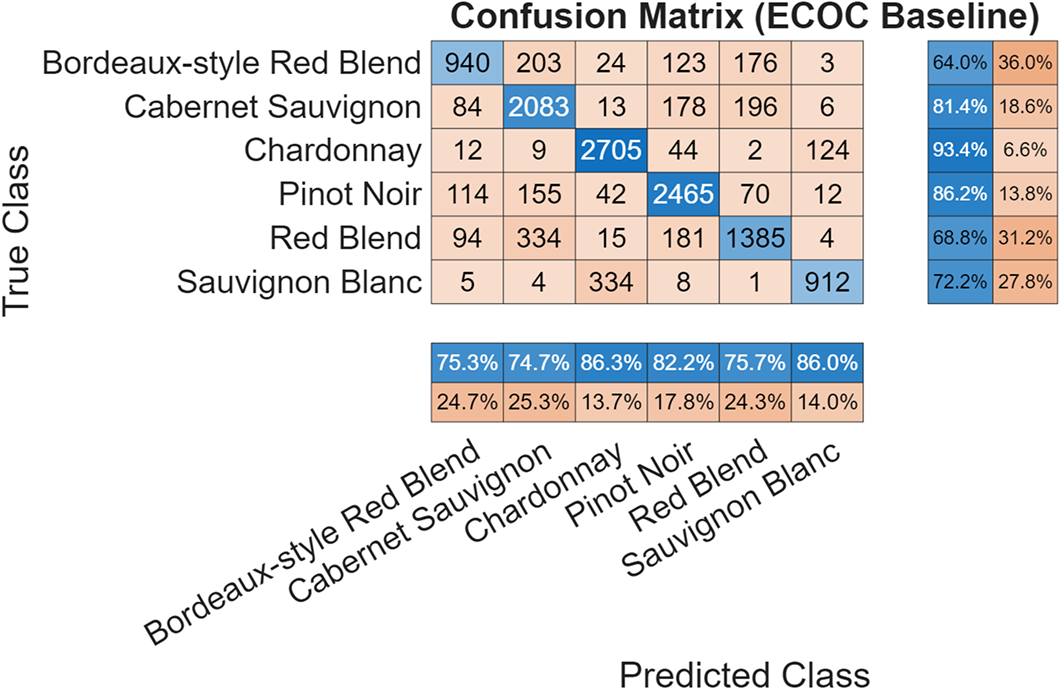
BERT consistently outperforms ECOC across all varieties, with particularly strong improvements for red wines that share similar descriptive vocabulary. The confusion matrices tell the full story:
ECOC Baseline Performance: 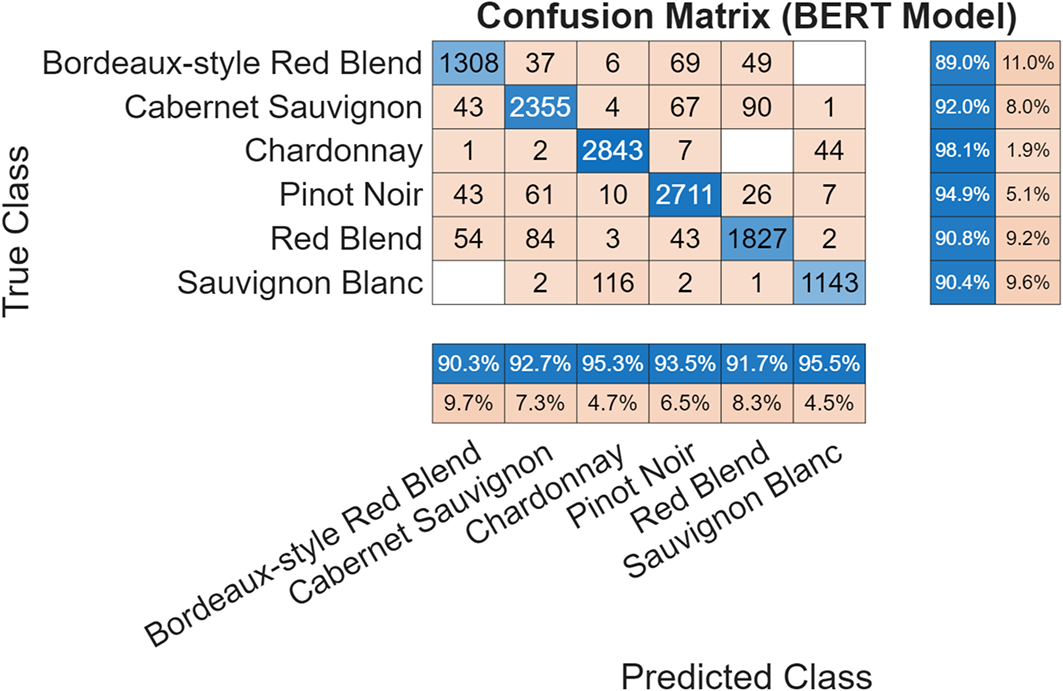
The classical approach shows significant confusion between red varieties—Bordeaux-style Red Blend, Cabernet Sauvignon, and Red Blend frequently misclassify as each other, reflecting their overlapping descriptive vocabulary.
BERT Performance: 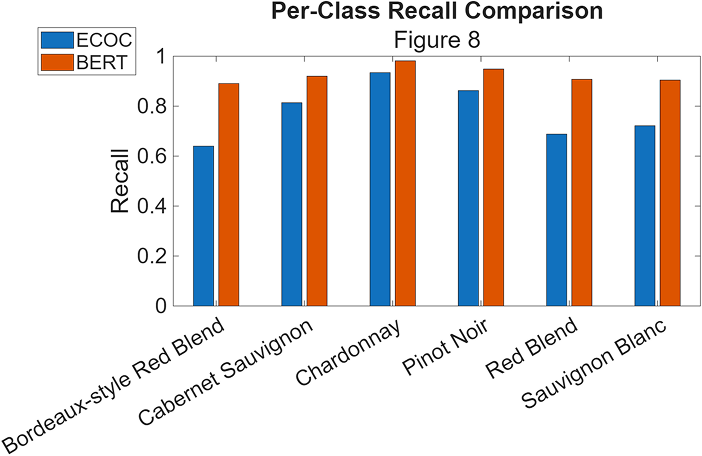
BERT dramatically reduces these confusions, achieving 94.1% overall accuracy with strong per-class performance (89-98% recall). The model successfully distinguishes between stylistically similar wines that stymied the classical approach.
Scalability Analysis
To test generalization, I also evaluated BERT on a 20-class problem spanning more grape varieties:
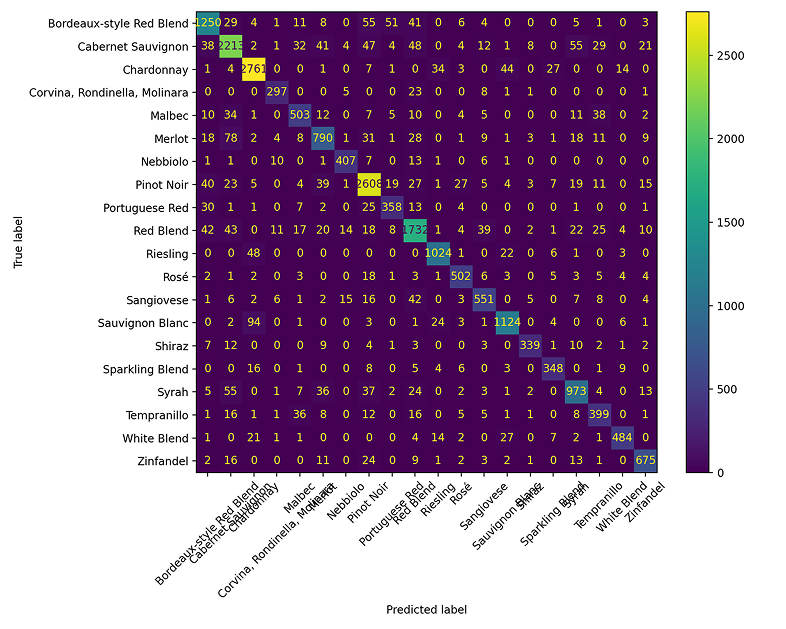
Even with increased complexity, BERT maintains strong performance, achieving 87% accuracy across 20 wine varieties. This suggests the contextual understanding scales well beyond the simplified 6-class comparison.
Results
The transformer approach decisively outperformed classical methods:
- BERT: 94.1% accuracy, 89-98% per-class recall
- ECOC: ~80% average accuracy, significant confusion between red varieties
- Key insight: Contextual understanding dramatically improves classification of semantically similar classes
The performance gap was most pronounced for red wine varieties that share descriptive vocabulary. BERT’s ability to understand context—how “cherry” differs when paired with “oak” versus “mineral”—proved crucial for disambiguation.
Interestingly, both approaches handled white wines (Chardonnay, Sauvignon Blanc) relatively well, suggesting these varieties have more distinctive vocabulary patterns that even TF-IDF can capture.
Lessons Learned
This project crystallized several important insights about NLP methodology:
Context matters more than vocabulary. The classical pipeline’s failure wasn’t due to poor feature engineering—SVD revealed meaningful latent structure in the text. Rather, bag-of-words representations fundamentally cannot capture the contextual relationships that distinguish similar wine styles.
Domain expertise has limits. While I could have engineered more sophisticated features (n-grams, wine-specific dictionaries), the transformer’s end-to-end learning proved more effective than manual feature design.
Interpretability vs. performance is real. The classical pipeline offered clear feature attribution—I could examine which terms drove classifications. BERT’s superior performance came at the cost of explainability, highlighting a fundamental tradeoff in model selection.
Scale changes everything. The 20-class experiment showed that performance gaps widen with problem complexity, suggesting transformers’ advantages compound in realistic scenarios.
Links
- GitHub Repository: WineDetection
- Course: Quantitative Engineering Analytics 1, Olin College
- Collaborator: Allie Vu
- Dataset: Wine Enthusiast Reviews (Kaggle)